- ScholarSphere Newsletter
- Posts
- ScholarSphere Newsletter #26
ScholarSphere Newsletter #26
Where AI meets Academia
Welcome to edition 26 of ScholarSphere
"Intelligence is not to make no mistakes, but to see quickly how to make them good." Bertolt Brecht (1898-1956)
Welcome to our AI Newsletter—your ultimate guide to the rapidly changing world of AI in academia. If you haven't joined us yet, now's your chance! Click that button, subscribe with your email, and get ready for an exciting journey through all things AI in the academic realm!
In today's search of AI, we'll see...
Deep Dive into AI: Expand Your Knowledge
The blog post "Supervised Fine-Tuning: How to Customize Your LLM?" by the Toloka Team outlines the significance of supervised fine-tuning (SFT) in adapting large language models (LLMs) for specific natural language processing (NLP) tasks. SFT serves as a bridge between pre-trained models and task-specific requirements, allowing models to refine their capabilities with minimal additional training. This method leverages labeled data to guide the model's adjustment process, enhancing its performance on specific tasks by providing clear feedback during training. The process involves presenting the model with input-output pairs to learn patterns and relationships tailored to the target task. SFT has been instrumental in achieving high outcomes across various NLP tasks, including sentiment analysis, machine translation, and language generation, by enabling models to generalize better across tasks and domains. It allows for efficient learning from limited task-specific labeled data, addressing data scarcity issues prevalent in real-world applications. The paper emphasizes that fine-tuning transforms pre-trained models into specialized tools capable of executing defined actions proficiently.

Image credit to Jonstokes.com
Key Points:
Purpose of SFT: Adapts pre-trained models for specific NLP tasks.
Role of Labeled Data: Guides model adjustment with clear feedback.
Efficiency: Allows learning from limited task-specific data.
Applications: Used in sentiment analysis, machine translation, etc.
Design and Findings
Supervised fine-tuning involves several steps, including task definition, model selection, data preparation, and model fine-tuning. Data scientists first outline the assignments the LLM should perform, such as question answering or text classification, and choose a suitable pre-trained model. They gather relevant labeled datasets and tokenize the text inputs for processing. The fine-tuning process uses supervised learning approaches, updating model parameters through back-propagation based on the loss function's gradient. This process includes hyper-parameter tuning to optimize model performance, evaluated on a validation set to prevent overfitting. The findings highlight that SFT significantly improves model performance on downstream tasks compared to directly applying a pre-trained model, due to the updated model parameters. The blog also notes that obtaining high-quality labeled data is crucial for successful fine-tuning, often requiring domain expertise and careful quality control.

Image credit to LinkedIn, Tushar Aggarwal
Key Points:
Steps in SFT: Task definition, model selection, data preparation, fine-tuning.
Model Selection: Choose models like BERT, GPT, LLaMA for tasks.
Fine-Tuning Process: Involves updating parameters and hyper-parameter tuning.
Importance of Data Quality: High-quality labeled data is crucial.
Types of Supervised Fine-Tuning
The article discusses different types of supervised fine-tuning, including full fine-tuning, parameter-efficient fine-tuning (PEFT), and instruction fine-tuning. Full fine-tuning updates all model parameters using labeled data, requiring significant computational power but offering maximum flexibility for adaptation. PEFT, on the other hand, only modifies a portion of the weights, adding task-specific layers or adapters, which reduces computational costs while maintaining competitive performance. Instruction fine-tuning involves providing the model with labeled examples that guide its expected behavior, improving its ability to follow specific instructions. Each type of fine-tuning is tailored to specific needs, balancing computational efficiency with the depth of model adaptation required. The choice of fine-tuning method depends on the resources available and the desired level of customization for the model.

Key Points:
Full Fine-Tuning: Updates all parameters, requires high computational power.
PEFT: Modifies only part of the weights, reducing costs.
Instruction Fine-Tuning: Uses labeled examples to guide behavior.
Customization Needs: Choice depends on resources and required adaptation.
Brief Explanation of Supervised Fine-Tuning
Supervised fine-tuning is a technique used to adapt pre-trained language models to specific tasks by using labeled data. It involves retraining the model on a smaller, task-specific dataset, allowing it to learn patterns relevant to the task at hand. For example, a pre-trained model like BERT can be fine-tuned on a sentiment analysis dataset, where the input data consists of text snippets labeled with sentiment categories. By adjusting the model's parameters based on this labeled data, the model becomes more adept at identifying sentiment in new, unseen text. This process enhances the model's accuracy and performance for the specific application, leveraging the foundational knowledge acquired during pre-training. Fine-tuning is particularly beneficial when the task requires precise language understanding or domain-specific insights, making it a cornerstone of modern NLP model development.
Key Points:
Purpose: Adapts pre-trained models to specific tasks.
Process: Uses labeled data for task-specific learning.
Example: Fine-tuning BERT for sentiment analysis.
Benefits: Enhances accuracy and task-specific performance.
You can also find extra teaching articles in our LinkedIn Page.
Join us Now in ScholarSphere
Mastering AI: Prompt Perfection
ReAct: Synergizing Reasoning and Acting in Language Models (Link)
By Shunyu Yao, et al. (2022)
Summarized by You.com (GPT4o)

ReAct components You can implement ReAct prompting for any LLM workflow that involves reasoning, decision-making, action planning, and external knowledge. You need the following key components for ReAct.
Image credit to width.ai
The paper introduces ReAct, a paradigm that combines reasoning and acting within large language models (LLMs) to enhance their performance on diverse language and decision-making tasks. Traditional LLMs have excelled in reasoning and decision-making separately, but ReAct proposes an integrated approach where reasoning traces guide action plans and actions are used to gather external information to improve reasoning. This method addresses limitations like fact hallucination and error propagation seen in chain-of-thought (CoT) reasoning. ReAct has been evaluated on tasks such as question answering (HotpotQA), fact verification (Fever), and interactive decision-making in environments like ALFWorld and WebShop, showing improvements over state-of-the-art baselines. By using a simple Wikipedia API, ReAct effectively reduces hallucinations and creates human-like task-solving trajectories. For instance, in ALFWorld and WebShop, ReAct outperforms imitation and reinforcement learning methods with a significant success rate increase, demonstrating the synergy of reasoning and acting.

Comparison of (a) Act-only and (b) ReAct prompting to solve an AlfWorld game. In this domain, we omit in-context examples in the prompt, and only show task solving trajectories generated by the model (Act, Thought) and the environment (Obs).
Image credit to Shunyu Yao, et al. (2022)
Key Points:
Integration: Combines reasoning and acting in LLMs.
Applications: Effective in QA, fact verification, and decision-making tasks.
Performance: Outperforms baselines, reduces hallucinations.
Methodology: Uses Wikipedia API for enhanced reasoning.
Research Design and Findings
The research involves prompting LLMs with ReAct, which generates reasoning traces and actions interleaved for task-solving. The method was tested on four benchmarks, including HotpotQA and Fever for knowledge-intensive tasks and ALFWorld and WebShop for interactive decision-making. The experiments showed that ReAct performs better than both reasoning-only and action-only models by utilizing the strengths of both approaches. The study also explored combining ReAct with CoT for better accuracy and factuality. Findings indicate that ReAct's ability to access external information makes it more grounded and trustworthy, although it may occasionally lead to reasoning errors due to structural constraints. The paper highlights the importance of sparse reasoning and the ability to dynamically adjust plans based on new information.

Image credit to Shunyu Yao, et al. (2022)
Key Points:
Types of Prompting and Evaluation
The paper examines different prompting strategies, including standard, CoT, act-only, and ReAct. ReAct's prompting involves both reasoning and actions, allowing the model to interact with environments and gather information dynamically. The evaluation showed that ReAct outperformed other methods, especially in tasks requiring external information retrieval. For example, in WebShop, ReAct's reasoning helps identify relevant product attributes, outperforming imitation and reinforcement learning methods. The study emphasizes the value of combining internal reasoning with external feedback, showcasing ReAct as a pioneering approach in closed-loop systems. The paper also discusses the potential of ReAct to improve with fine-tuning and more human annotations.
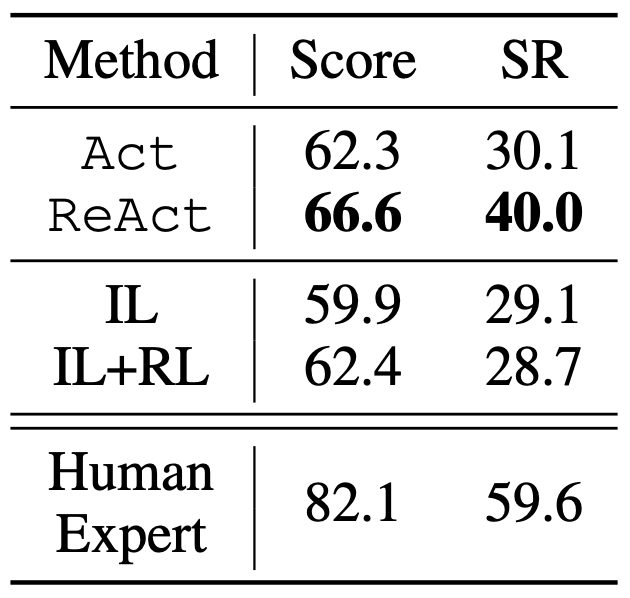
Table 4: Score and success rate (SR) on Webshop. IL/IL+RL taken from Yao et al. (2022).
image credit to Shunyu Yao, et al. (2022)
Key Points:
Prompting Strategies: ReAct combines reasoning and actions.
Evaluation: Shows superior performance, especially in interactive tasks.
External Feedback: Demonstrates the importance of external information.
Fine-tuning: Potential for improvement with more data.
Brief Explanation of ReAct Prompting
ReAct prompting is a method where language models generate interleaved reasoning and actions to solve tasks. This approach allows the model to dynamically adjust plans and interact with environments to gather information, thus enhancing its reasoning capabilities. For example, in a decision-making task like ALFWorld, ReAct uses reasoning to decide which objects to interact with and actions to execute based on the current state. This synergy of reasoning and acting helps the model achieve better task performance and human-like interpretability. ReAct is particularly effective in scenarios where external information is crucial, as it enables the model to access and incorporate this data into its reasoning process.
Key Points:
Purpose: Enhances task-solving by combining reasoning and actions.
Process: Interleaves reasoning and actions for dynamic adjustment.
Example: Used in ALFWorld for decision-making tasks.
Effectiveness: Improves performance and interpretability.
For reading the full text click here
Full getting access to our Prompt Inventory check here
Don’t forget to visit our LinkedIn Page
Cutting-Edge AI Insights for Academia


Ray Schroeder is Professor Emeritus, Associate Vice Chancellor for Online Learning at the University of Illinois Springfield (UIS) and Senior Fellow at UPCEA
Deloitte Center for Government Insights: How higher education can realize the potential of Generative AI

University of Texas at Austin: AI in EDU: UT Austin introduces new AI support for teaching and learning

Paper of the week: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, by Jacob Devlin, et al. (2018)

Spotlight on AI Tools for Academic Excellence

By Microsoft Designer
Prompt: A hyper realistic image of a modern startup workspace with a communal table, multiple laptops, and wooden chairs. The workspace should have a moss wall on one side and be in steel blue, cinnamon, and saffron colors with natural, mid-morning light in a photorealistic style.
MyLens.ai: Generate beautiful timelines with AI; Simplify Anything, Visually. MyLens AI explains anything with easy visuals.
Replit: An AI-powered software development & deployment platform for building, sharing, and shipping software fast.
AIAssistWorks: Access 50+ AI models in Google Sheets™ effortlessly. Save and reuse prompts. Use Perplexity online model and Groq Fast API.
CIBN Connect (LeadGenie - Chrome Extension) : AI-powered lead generation via LinkedIn.
For finding more featured and selected AI tools & apps, please subscribe to ScholarSphere Newsletter Series
Reply