- ScholarSphere Newsletter
- Posts
- ScholarSphere Newsletter #16
ScholarSphere Newsletter #16
Where AI meets Academia
Welcome to 16th edition of ScholarSphere
“I guess Surrealism has a draw for me because it's an unknown world. It's a world of subconscious. Some things you can't really get your hands on very easily. Things that are kind of nebulous and they feel like they're not completely formed. You have to feel your way through that.” Gotye
Welcome to our AI Newsletter—your ultimate guide to the rapidly changing world of AI in academia. If you haven't joined us yet, now's your chance! Click that button, subscribe with your email, and get ready for an exciting journey through all things AI in the academic realm!
In today's search of AI, we'll see...
Deep Dive into AI: Expand Your Knowledge
Intrinsic Motivation in Model-based Reinforcement Learning: A Brief Review
By Artem Latyshev and Aleksandr I. Panov (2023)
Summarized by prompting in You.com (GPT4-o)

Reinforcement Learning (RL) is a type of machine learning where agents learn by interacting with their environment through trial and error, receiving rewards or penalties. The primary goal is to maximize cumulative rewards by learning optimal behaviors and actions. This article on Medium delves into RL and its model-based variant, explaining the fundamental concepts and their applications. Key points include the distinction between model-free and model-based RL, with the latter using a model of the environment's dynamics to make predictions and decisions. The article further explores how model-based RL can lead to more efficient learning and better performance in complex tasks. This approach is particularly beneficial in scenarios where data is scarce or expensive to obtain.

Fig 2. Overview of our model-based reinforcement learning algorithm.
Model-based reinforcement learning involves building a model of the environment to predict future states and rewards. This model helps the agent plan its actions more effectively by simulating different scenarios and choosing the best course of action. The article provides examples of model-based RL applications, such as robotics and autonomous driving, where understanding the environment's dynamics is crucial. By using a model, agents can make more informed decisions, leading to faster learning and better performance. This approach contrasts with model-free RL, where agents rely solely on experience and received rewards, often requiring more data and time to learn optimal behaviors.

A non-exhaustive, but useful taxonomy of algorithms in modern RL.
Picture Credit to OpenAI Spinning up
The article highlights several advantages of model-based RL, including improved sample efficiency and the ability to adapt to new environments more quickly. By leveraging a model, agents can generalize their learning to different tasks and situations, making them more versatile and robust. The paper also discusses the challenges associated with model-based RL, such as the complexity of building accurate models and the computational resources required. Despite these challenges, the potential benefits of model-based RL make it a promising area of research and application in the field of artificial intelligence.

In conclusion, understanding the differences between model-free and model-based reinforcement learning is essential for developing effective AI systems. Model-based RL offers significant advantages in terms of efficiency and adaptability, making it suitable for complex and dynamic environments. The article emphasizes the importance of continued research and development in this area to overcome current limitations and unlock the full potential of model-based approaches. As AI continues to evolve, model-based reinforcement learning is likely to play a crucial role in advancing the capabilities of intelligent agents and their applications in various industries.
For reading the full article and practical examples, click here.
You can also find extra teaching articles in our LinkedIn Page.
Mastering AI: Prompt Perfection
Graph of Thoughts (GoT): Solving Elaborate Problems with Large Language Models
By Maciej Besta, et al. (2024),
The Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI-24)
Summarized by You.com

The paper "Beyond Chain-of-Thought, Effective Graph-of-Thought Reasoning in Language Models" by Yao Yao, Zuchao Li, and Hai Zhao (2024) explores a novel approach to improving the reasoning capabilities of language models (LMs). Traditional Chain-of-Thought (CoT) prompting enables LMs to perform complex reasoning tasks by generating intermediate steps in a sequential manner. However, the authors argue that human thought processes are inherently non-linear, often involving sudden leaps and connections between seemingly unrelated ideas. To address these limitations, they propose the Graph-of-Thought (GoT) reasoning technique, which models human thought processes as a graph rather than a simple chain. By representing thought units as nodes and their connections as edges, GoT captures the non-sequential nature of human thinking, allowing for more realistic and effective modeling of reasoning processes.

The GoT framework adopts a two-stage approach, consisting of rationale generation and answer inference. During the rationale generation stage, the model generates rationales based on the input text and the constructed thought graph. The thought graph is built using an Extract-Cluster-Coreference (ECC) process, which extracts deductive triplets and clusters nodes that refer to the same mentions. This process enables the model to simulate human deductive reasoning by connecting and recombining ideas in a non-sequential manner. In the answer inference stage, the predicted rationales are concatenated with the input text, and the final answer is generated by leveraging the graph representation. The GoT framework is evaluated on text-only reasoning tasks and multimodal reasoning tasks, demonstrating significant improvements over traditional CoT methods.

The experimental results highlight the effectiveness of the GoT approach. On the AQUA-RAT dataset, the GoT model achieves a substantial improvement in accuracy compared to strong CoT baselines. Specifically, the GoT model boosts accuracy from 85.19% to 87.59% using the T5-base model, demonstrating its superior performance in maintaining resources and overall reasoning tasks. Additionally, in the multimodal ScienceQA task, the GoT model outperforms the state-of-the-art Multimodal-CoT model by achieving an accuracy of 87.59% compared to 85.19%. These results underscore the potential of GoT in enhancing the reasoning capabilities of LMs by incorporating the non-linear nature of human thought processes.
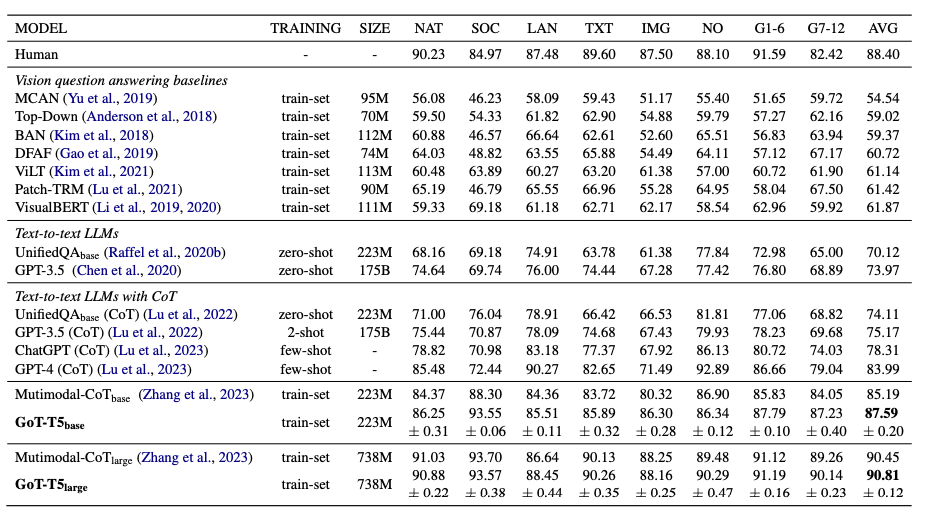
Table 2: Main test accuracy results (%) of ScienceQA. SIZE=backbone model size. Question classes: NAT = natural science, SOC = social science, LAN = language science, TXT = text context, IMG = image context, NO = no context, G1-6 = grades 1-6, G7-12 = grades 7-12, AVG= average accuracy scores
The paper also discusses the broader implications and future directions of the GoT approach. The authors emphasize that GoT provides a more comprehensive and nuanced representation of human reasoning, enabling LMs to better understand and solve complex problems. They suggest that future research could extend the GoT framework to incorporate cooperative and competitive actions by other agents, further validating its effectiveness in more complex settings. Additionally, the authors highlight the importance of continued research and development in this area to overcome current limitations and unlock the full potential of GoT in advancing the capabilities of intelligent agents. The research was supported by various grants, and the code for the GoT framework is publicly available for further exploration and validation.
For reading the full article and practical examples, click here.
Full getting access to our Prompt Inventory check here
Don’t forget to visit our LinkedIn Page
Cutting-Edge AI Insights for Academia




KEALTF: The Knowledge Enrichment and Adaptive Learning/Teaching Framework (KEALTF) by H. G. Khiem, et al. (2024)

Paper of the week: Artificial Intelligence in Education World: Opportunities, Challenges, and Future Research Recommendations by Ghasa Faraasyatul ‘Alam, et al. (2024)
Figure 4. Density Visualization from Artificial Intelligence in Education World: Future Research Recommendations
Spotlight on AI Tools for Academic Excellence

GauthMath : Your AI Homework Helper Gauth it, Ace it!
InvideoAI: Create videos with text prompts, Publish-ready videos with zero video creation skills. Type any topic and invideo AI creates a video with script, visuals, subtitles, voiceover & music.
Gliglish: Learn languages by speaking with AI: Talk to a teacher. Roleplay real-life situations. Improve your speaking & listening.
Periodic Table: Immerse yourself in Chemistry with our 3D Periodic Table app., Complete interactive map of elements

For finding more selected ai apps, please subscribe to ScholarSphere Newsletter Series
Reply