- ScholarSphere Newsletter
- Posts
- ScholarSphere Newsletter #25
ScholarSphere Newsletter #25
Where AI meets Academia
Welcome to edition 25 of ScholarSphere
“Making money is often more fun than spending it, though I personally have never regretted money I've spent on friends, new experiences, saving time, travel, and causes I believe in.”
Sam Altman, CEO of OpenAI (1985-)
Welcome to our AI Newsletter—your ultimate guide to the rapidly changing world of AI in academia. If you haven't joined us yet, now's your chance! Click that button, subscribe with your email, and get ready for an exciting journey through all things AI in the academic realm!
In today's search of AI, we'll see...
Deep Dive into AI: Expand Your Knowledge
Token Optimization: A Comprehensive Guide
By Supal Kanti Chowdhury, IBM Developer website, 29 August 2024
Summarized by Google Gemini

Image credit to developer.ibm.com
Introduction
Token optimization is a pivotal aspect of prompt engineering, significantly impacting the efficiency, cost-effectiveness, and overall performance of large language models (LLMs). By understanding and implementing effective token optimization strategies, you can enhance the accuracy, relevance, and scalability of your AI solutions.
Understanding Tokens and Their Significance
Tokens are the fundamental units of text processed by LLMs, typically smaller than words. Efficient token usage is crucial for optimizing prompt engineering, as it directly affects the cost and performance of LLM-based applications.
The Importance of Token Optimization
Token optimization offers several key benefits:
Cost Reduction: Minimizing tokens can significantly reduce the financial burden of using LLMs, as each token processed incurs a cost.
Improved Performance: Fewer tokens lead to reduced computational load, resulting in faster response times and enhanced efficiency.
Optimized Resource Utilization: Efficient token usage helps in optimizing the use of computational resources, especially in large-scale applications.
Enhanced User Experience: Clear and concise prompts, achieved through token optimization, lead to better user understanding and interaction.
Scalability: Effective token optimization ensures that your LLM-based solutions remain scalable and performant as the workload increases.
Techniques for Token Optimization

Image credit to Winder.ai
Minimizing Token Count:
Concise and Clear Prompts: Craft prompts that are direct and avoid unnecessary details.
Abbreviations and Acronyms: Use appropriate abbreviations and acronyms to reduce token count.
Redundancy Removal: Eliminate redundant or duplicated words and information.
Subword Tokenization: Consider using models optimized for subword tokenization to handle out-of-vocabulary words more efficiently.

Image credit to Winder.ai
Efficient Context Provision:
Structured Context: Organize contextual information into bullet points or lists for better processing.
Redundancy Reduction: Remove unnecessary details from the context.
Highlight Key Points: Focus on the most important information relevant to the task.
Effective Chunking:
Semantic Chunking: Divide information into smaller, meaningful units to improve focus and accuracy.
Optimize Token Usage: Break down complex prompts into semantically coherent chunks to reduce token count and improve efficiency.

Leveraging Pre-trained Models
Utilizing pre-trained models can significantly enhance token optimization:
Optimized Tokenization: Many pre-trained models come with optimized tokenization methods, such as subword tokenization, which can reduce token count and improve performance.
Domain-Specific Knowledge: Pre-trained models can provide valuable domain-specific knowledge, reducing the need for extensive training on your data.
Scalability: Pre-trained models are often designed to scale efficiently, handling large-scale applications effectively.
Best Practices for Token Optimization
Document and Analyze Prompts: Keep a record of prompts and their performance metrics to identify areas for improvement.
Regular Testing and Validation: Continuously test and validate prompts using diverse inputs to ensure robustness.
Iterative Refinement: Establish a feedback loop to refine prompts based on user feedback and model performance.
Consider Model-Specific Guidelines: Refer to the documentation of the specific LLM you are using for any model-specific token optimization recommendations.
Conclusion
Token optimization is a crucial aspect of prompt engineering that can significantly enhance the performance, cost-effectiveness, and scalability of your LLM-based applications. By effectively implementing the techniques outlined in this guide, you can optimize token usage, reduce costs, and improve the overall accuracy and relevance of your generated outputs.
You can also find extra teaching articles in our LinkedIn Page.
Join us Now in ScholarSphere
Mastering AI: Prompt Perfection
Chain-of-Symbol Prompting for Spatial Reasoning in Large Language Models (Link)
By Hanxu Hu, et al. (2024)
Summarized by You.com (GPT4o)
The paper introduces the Chain-of-Symbol (COS) prompting method, which aims to enhance the performance of large language models (LLMs) in complex spatial reasoning tasks. The authors investigate the limitations of existing LLMs in handling spatial relationships represented in natural language and propose COS as a solution that uses condensed symbols to represent these relationships. By conducting experiments on three spatial reasoning tasks - Brick World, NLVR-based Manipulation, and Natural Language Navigation - the authors demonstrate that COS significantly outperforms traditional Chain-of-Thought (CoT) prompting methods. The results reveal that COS leads to an impressive accuracy increase of up to 60.8% on the Brick World task, achieving up to 92.6% accuracy compared to CoT. Furthermore, COS reduces the number of input tokens by approximately 65.8%, making it a more efficient alternative for prompting LLMs. The study's findings indicate that symbolic representations can facilitate better understanding and reasoning for LLMs, which often struggle with complex spatial descriptions in natural language. The use of COS could pave the way for more effective applications of LLMs in various spatial reasoning scenarios.

Figure 2: example triples for our three proposed tasks: Brick World, NLVR-based Manipulation, and Natural Language Navigation, and SPARTUN dataset (Mirzaee & Kordjamshidi, 2022). Chains of Symbols are highlighted.
Image Credit to Hanxu Hu, et al. (2024)
Key Points:
Introduction of COS: A new prompting method for enhancing spatial reasoning in LLMs.
Limitations of LLMs: Existing models struggle with understanding spatial relationships in natural language.
Performance Improvement: COS shows up to 60.8% accuracy improvement over CoT prompting.
Efficiency in Token Usage: COS reduces input token counts by approximately 65.8%.
The research design involved evaluating the performance of LLMs, specifically GPT-3.5-Turbo and LLaMA-2, on both existing and newly created spatial reasoning tasks. The authors conducted extensive experiments on three primary tasks, each designed to challenge the models in spatial understanding and planning. Additionally, they employed a zero-shot approach to generate Chain-of-Thought demonstrations, which were then converted into COS format by replacing natural language descriptions with symbols. The evaluation metrics included accuracy, precision, and recall, allowing for a comprehensive assessment of model performance. The results indicated that COS consistently outperformed CoT across all tasks, demonstrating enhanced reasoning capabilities and stability in outputs. The authors also explored the robustness of COS across different languages and symbols, confirming its effectiveness beyond English and its adaptability to various symbolic representations. Overall, the research highlights the advantages of symbolic representation in prompting LLMs for complex reasoning tasks.

Figure 4: Scaling curve of CoS and CoT of Llama-2 on three tasks.
Image Credit to Hanxu Hu, et al. (2024)
Key Points:
Research Design: Evaluation of LLM performance on spatial reasoning tasks.
Zero-Shot Approach: Generating Chain-of-Thought demonstrations for conversion to COS.
Evaluation Metrics: Accuracy, precision, and recall used for performance assessment.
Robustness Across Languages: COS performs well in different languages and with various symbols.
The findings demonstrate that COS not only enhances model accuracy but also improves the efficiency of the prompting process. The experiments revealed that COS achieved substantial gains in performance while significantly reducing the number of tokens required for intermediate steps. For instance, in the Brick World task, COS reduced the input tokens from 407 to just 139, allowing for more cost-effective interactions with LLMs. Further analysis indicated that COS provides a more structured and clear representation of spatial relationships, making it easier for LLMs to grasp complex scenarios. The authors also noted that as LLMs scale in size, their ability to understand abstract symbols improves, leading to even greater performance benefits from COS. The study emphasizes the potential of symbolic representations in enhancing the capabilities of LLMs, particularly in tasks requiring intricate reasoning and planning.

Table 3: The automatic evaluation results with GPT-3.5-Turbo and GPT-4 on SPARTUN dataset. We apply CoT with 5 shots, and CoS with 5 shots (Ours) respectively. We report the number of tokens in the intermediate steps from demonstrations as the last column.
Image Credit to Hanxu Hu, et al. (2024)
Key Points:
Performance and Efficiency Gains: COS improves accuracy while reducing token usage.
Structured Representation: Offers clearer spatial relationship representations.
Scalability Benefits: Larger models show improved symbol understanding with COS.
The conclusion of the paper highlights the promising results of using Chain-of-Symbol prompting in spatial reasoning tasks. The authors stress the importance of exploring symbolic representations to improve LLM performance, particularly in complex environments that challenge current models. They advocate for further research into the application of COS across various domains and tasks, suggesting that it could significantly enhance the capabilities of LLMs in understanding and reasoning about spatial relationships. Additionally, the authors acknowledge the limitations of their study, including the need for more extensive evaluations across different models and tasks to fully validate the robustness of COS. The research sets a strong foundation for future work aimed at integrating symbolic reasoning techniques within language models to achieve more effective and efficient processing of spatial information.
Key Points:
Promising Results: COS shows strong potential in spatial reasoning tasks.
Call for Further Research: Encourages exploration of COS in diverse applications.
Study Limitations: Acknowledges need for broader evaluations to validate findings.
Explanation of Chain of Symbols Prompting
Chain of Symbols (COS) prompting is a technique that represents spatial relationships using condensed symbols instead of conventional natural language descriptions. This method aims to simplify and clarify the intermediate reasoning processes required for complex tasks, particularly in spatial reasoning scenarios. By using symbols, COS reduces the amount of redundant text and enhances the model's ability to understand and process relationships more efficiently.

Natural Language Navigation
Image Credit to Hanxu Hu, et al. (2024)
Example:
Natural Language Prompt: "The yellow brick C is on top of the brick E. The yellow brick D is on top of the brick A."
COS Representation: "C/E; D/A," where "/" symbolizes the spatial relationship of "on top of."
This symbolic representation allows the model to focus on the essential relationships and operations required to solve the task, significantly improving performance and reducing token usage.
For reading the full text click here
Full getting access to our Prompt Inventory check here
Don’t forget to visit our LinkedIn Page
Cutting-Edge AI Insights for Academia


Image credit to Synthesia.io
.png?utm_source=scholarsphere.beehiiv.com&utm_medium=referral&utm_campaign=scholarsphere-newsletter-25)
Image credit to springsapps.com

AI3 Interim Director Steve Skiena
CampusTechnology: New The American Association of Colleges and Universities (AAC&U) Institute to Explore Challenges and Opportunities of AI in Teaching and Learning


Paper of the Week: Direct Preference Optimization: Your Language Model is Secretly a Reward Model by Rafael Rafailov, et al. (2023)
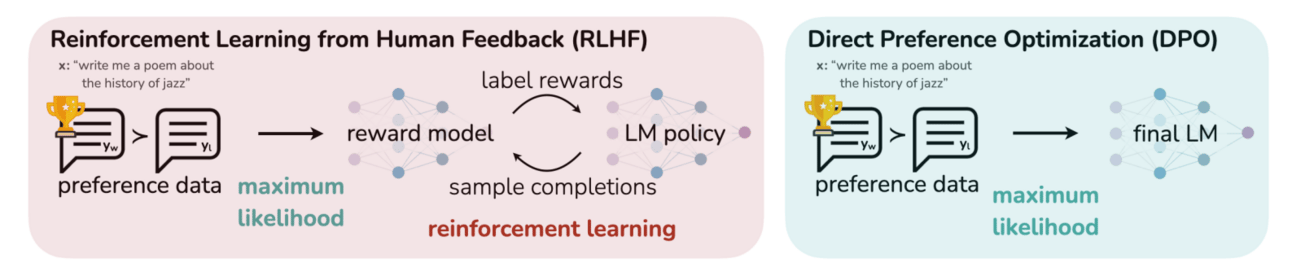
Figure 1: DPO optimizes for human preferences while avoiding reinforcement learning. Existing methods for fine-tuning language models with human feedback first fit a reward model to a dataset of prompts and human preferences over pairs of responses, and then use RL to find a policy that maximizes the learned reward. In contrast, DPO directly optimizes for the policy best satisfying the preferences with a simple classification objective, fitting an implicit reward model whose corresponding optimal policy can be extracted in closed form.
Spotlight on AI Tools for Academic Excellence

By Microsoft Designer
Prompt: Cutaway view of a modern university in the style of a technical architectural illustration. The illustration includes shades of red, coral, grey, blue, cream and green. The background is a beautiful green space.
PromptOpti: Automated Prompt Testing For Enhanced Security, Reduce Cost, Precise Responses, Lower Latency; End-to-End Prompt Testing For Safer, Preciser, Faster LLM apps.

ClioApp.ai: AI that understands your business, instantly; Enable your employees to spend time taking critical decisions and driving business growth. AI powered workplace search that connects with all your workplace apps.
Winder.ai: Winning Businesses Use Unstoppable AI Award-winning Enterprise AI Agency delivering AI for Business.

Klu.ai: Design, deploy, and optimize Generative AI apps with Klu; Confidently iterate and evaluate your AI Collaborate on prompts, evaluate, and optimize LLM-powered Apps with Klu.
ibl.ai: Empowering Educators with Generative AI Our enterprise platform provides ready-to-go web and native apps for tutoring, content creation and revenue generation. You own all the code, data and models. Proven by NVIDIA, AWS and Google.
For finding more featured and selected AI tools & apps, please subscribe to ScholarSphere Newsletter Series
Reply