- ScholarSphere Newsletter
- Posts
- ScholarSphere Newsletter #27
ScholarSphere Newsletter #27
Where AI meets Academia
Welcome to edition 27 of ScholarSphere
"The function of education is to teach one to think intensively and to think critically. Intelligence plus character - that is the goal of true education."
Welcome to our AI Newsletter—your ultimate guide to the rapidly changing world of AI in academia. If you haven't joined us yet, now's your chance! Click that button, subscribe with your email, and get ready for an exciting journey through all things AI in the academic realm!
In today's search of AI, we'll see...
Deep Dive into AI: Expand Your Knowledge
An Introduction to Restricted Boltzmann Machines (Link) & A Practical Guide to Training RBMs (Link)
By Asja Fischer & Christian Igel (2012) & Geoffrey Hinton (2010)
Summarized by You.com (GPT4o)

Image credit to Latentview.com
The paper "An Introduction to Restricted Boltzmann Machines" by Asja Fischer and Christian Igel explores Restricted Boltzmann Machines (RBMs) as probabilistic graphical models and their applications in machine learning. RBMs are undirected graphical models that serve as building blocks for deep belief networks, effectively modeling the probability distribution of a dataset by learning from samples. The paper begins by introducing Boltzmann Machines (BMs) and how imposing restrictions on their network topology leads to the simpler, more efficient RBMs. Unlike BMs, RBMs feature two-layer structures with visible and hidden units, where visible units represent observable data and hidden units model dependencies. The paper discusses the learning process of RBMs, which relies on Markov chain Monte Carlo (MCMC) methods, particularly Gibbs sampling, to approximate the likelihood and its gradient. Through this process, RBMs can learn representations of data and generate new samples, useful for tasks such as image inpainting and texture generation. The authors emphasize the increased applicability of RBMs due to advancements in computational power and learning algorithms, making them pivotal in modern neural networks.

A Restricted Boltzmann Machine (RBM)
Image credit to Wikipedia.com
Key Points:
RBMs: Probabilistic graphical models used in machine learning.
Structure: Two-layer network with visible and hidden units.
Learning Process: Uses MCMC methods like Gibbs sampling.
Applications: Data representation and generation tasks.
Research Design and Findings
The research design involves a detailed exploration of the theoretical underpinnings of RBMs and their training algorithms. The paper discusses how RBMs, as generative models, represent probability distributions and learn from data through parameter adjustment. The training of RBMs is complex due to the computational intensity of calculating likelihoods, which is addressed through approximation methods like Contrastive Divergence (CD). The authors highlight different training algorithms, including Persistent Contrastive Divergence and Parallel Tempering, which improve upon basic CD by enhancing the mixing rate of the Gibbs chain and reducing bias. The paper also touches on the flexibility of RBMs in modeling binary and real-valued data, as well as their capacity to approximate any distribution on binary vectors. Despite their advantages, the authors note challenges in RBM training, such as the divergence of likelihood during learning, which requires careful parameter tuning and sometimes results in suboptimal solutions.

Restricted Boltzmann Machine, a complete analysis. Part 3: Contrastive Divergence algorithm
Image credit to Nguyễn Văn Lĩnh, Medium
Key Points:
Training Algorithms: Includes Contrastive Divergence and its variants.
Generative Capacity: RBMs can model complex data distributions.
Challenges: Computational complexity and parameter tuning issues.
Real-World Applications: Efficient in binary and continuous data modeling.

Geoffrey Hinton (1947-)
Image credit to Wikipedia.org
The paper "A Practical Guide to Training Restricted Boltzmann Machines" by Geoffrey Hinton provides an in-depth exploration of the technical aspects and best practices for training Restricted Boltzmann Machines (RBMs). RBMs are a type of stochastic neural network used for generative modeling, capable of learning representations of input data by capturing complex data distributions. The guide emphasizes the importance of selecting appropriate meta-parameters such as learning rates, momentum, and weight decay, which are crucial for effective training. The paper introduces Contrastive Divergence (CD) as a primary learning algorithm, which approximates the gradient of the data's log probability to update the network weights. Hinton also discusses various unit types, such as Gaussian and binomial units, that can be used in RBMs to handle different data types. The guide provides insights into monitoring learning progress, handling overfitting, and optimizing the number of hidden units to enhance model performance. By offering practical advice and recipes for various stages of training, the paper serves as a comprehensive resource for researchers and practitioners working with RBMs.
Key Points:
Training RBMs: Focus on learning rates, momentum, and weight decay.
Learning Algorithm: Contrastive Divergence is central to training.
Unit Types: Includes Gaussian and binomial units for diverse data.
Practical Guidance: Tips for monitoring progress and handling overfitting.
Research Design and Findings
The research design involves a systematic approach to understanding the mechanisms and challenges of training RBMs. Hinton explains the process of collecting statistics using Contrastive Divergence, emphasizing the need for stochastic updates of hidden states and careful adjustment of learning parameters. The findings suggest that proper initialization of weights and biases is critical, as it influences the model's ability to converge effectively and avoid local minima. The paper highlights the role of mini-batch sizes in influencing the efficiency and stability of gradient descent, advising on the optimal size for different datasets. Additionally, Hinton addresses advanced techniques like momentum and sparsity targets, which help in stabilizing learning and enhancing feature interpretability. The guide concludes that while RBMs can effectively model complex data, their success heavily depends on fine-tuning the training process and understanding the interplay of different hyperparameters.
Key Points:
Statistics Collection: Uses Contrastive Divergence for updates.
Parameter Initialization: Critical for effective convergence.
Mini-batch Sizes: Influences learning efficiency and stability.
Advanced Techniques: Includes momentum and sparsity for stability.
Explanation of Restricted Boltzmann Machines
Restricted Boltzmann Machines (RBMs) are a type of stochastic neural network used for unsupervised learning. They consist of visible units (which receive data) and hidden units (which learn to represent features), forming a bipartite graph where each visible unit connects to each hidden unit but not to other visible units. RBMs are trained to reconstruct input data by adjusting weights through learning algorithms like Contrastive Divergence. For example, in image processing, RBMs can learn to recognize patterns such as edges or shapes by capturing dependencies between pixels. By stacking RBMs into deep belief networks, higher-level features can be learned, potentially improving performance in classification tasks. RBMs are powerful tools in machine learning for representation learning and are particularly effective in scenarios where understanding the underlying data structure is crucial.

Image credit to Tijmen Tieleman (2009)
Key Points:
Structure: Bipartite graph with visible and hidden units.
Learning: Uses Contrastive Divergence to adjust weights.
Example: Recognizes patterns in image data.
Applications: Representation learning and deep networks.
Training a Restricted Boltzmann Machine
Training a Restricted Boltzmann Machine (RBM) involves several key steps to ensure effective learning and model performance. The process begins with initializing the weights to small random values and setting biases appropriately to avoid extreme probabilities that could hinder learning. The primary learning algorithm, Contrastive Divergence (CD), is applied to update the weights by calculating the difference between the data-driven expectations and the model's reconstructions. For instance, in the case of binary visible units, each unit's state is updated based on the logistic function of its total input, which helps in capturing data patterns. A typical application could be training an RBM on a dataset of handwritten digits, where the model learns to represent each digit as a combination of features captured by the hidden units. Adjusting learning rates and using momentum can further stabilize the training process, allowing the model to converge more efficiently. Overall, training an RBM requires careful consideration of hyperparameters and iterative refinement to achieve optimal data representation.

[Test Run] Restricted Boltzmann Machines Using C# By James McCaffrey
Image credit to Microsoft Learn
Key Points:
Initialization: Small random weights, appropriate bias settings.
Learning Algorithm: Contrastive Divergence updates weights.
Example: Capturing features in handwritten digit datasets.
Stabilization: Learning rates and momentum for efficient convergence.
You can also find extra teaching articles in our LinkedIn Page.
Join us Now in ScholarSphere
Mastering AI: Prompt Perfection
Active Prompting with Chain-of-Thought for Large Language Models (Link)
By Shizhe Diao, et al. (2024)
Summarized by You.com (GPT4o)

Figure 1: Illustrations of our proposed approach. There are four stages. (1) Uncertainty Estimation: with or without a few human-written chain-of-thoughts, we query the large language model k (k “ 5 in this illustration) times to generate possible answers with intermediate steps for a set of training questions. Then, we calculate the uncertainty u based on k answers via an uncertainty metric (we use disagreement in this illustration). (2) Selection: according to the uncertainty, we select the most uncertain questions for annotation. (3) Annotation: we involve humans to annotate the selected questions. (4) Inference: infer each question with the new annotated exemplars.
Image credit to Shizhe Diao, et al. (2024)
The paper "Active Prompting with Chain-of-Thought for Large Language Models" explores a novel method called Active-Prompt, designed to improve large language models (LLMs) in complex reasoning tasks. LLMs have shown limitations in reasoning tasks when using traditional in-context learning with chain-of-thought (CoT) prompting. CoT typically relies on a fixed set of human-annotated exemplars, which may not be optimal for all tasks. Active-Prompt addresses this by selecting the most informative questions for task-specific annotation using uncertainty-based active learning techniques. The research introduces several metrics, such as disagreement and entropy, to estimate uncertainty and identify questions that would benefit most from annotation. These selected questions are then annotated with rational chains to create effective exemplars, significantly boosting LLM performance across various reasoning tasks. Experimental results on eight datasets demonstrate that Active-Prompt outperforms existing methods by a substantial margin, highlighting the advantages of strategic question selection in CoT prompting.

Table 1: The overall performance of Active-Prompt. CoT and SC denote chain-of-thought (Wei et al., 2022) and self-consistency (Wang et al., 2022) methods. Bold denotes the best result
Image credit to Shizhe Diao, et al. (2024)
Key Points:
Active-Prompt: Enhances LLMs using uncertainty-based question selection.
CoT Limitations: Fixed exemplars may not suit all tasks.
Uncertainty Metrics: Utilizes disagreement and entropy for question selection.
Performance: Outperforms traditional methods on complex tasks.
Research Design and Findings
The research design involves evaluating Active-Prompt across several complex reasoning tasks, including arithmetic, commonsense, and symbolic reasoning. Using datasets like GSM8K and StrategyQA, the authors compare Active-Prompt against baseline models like Chain-of-Thought (CoT), Self-Consistency (SC), and Random-CoT. The results indicate that Active-Prompt, particularly when using disagreement and entropy as uncertainty metrics, consistently achieves higher accuracy than these baselines. The method's ability to reduce the human effort required for exemplar creation while maintaining high performance is also emphasized. The analysis reveals that Active-Prompt’s strategic selection of questions for annotation leads to more effective prompts, which in turn improve the model's reasoning capabilities. Moreover, the study demonstrates the robustness of Active-Prompt across different datasets and its potential for wider applicability in various reasoning contexts.
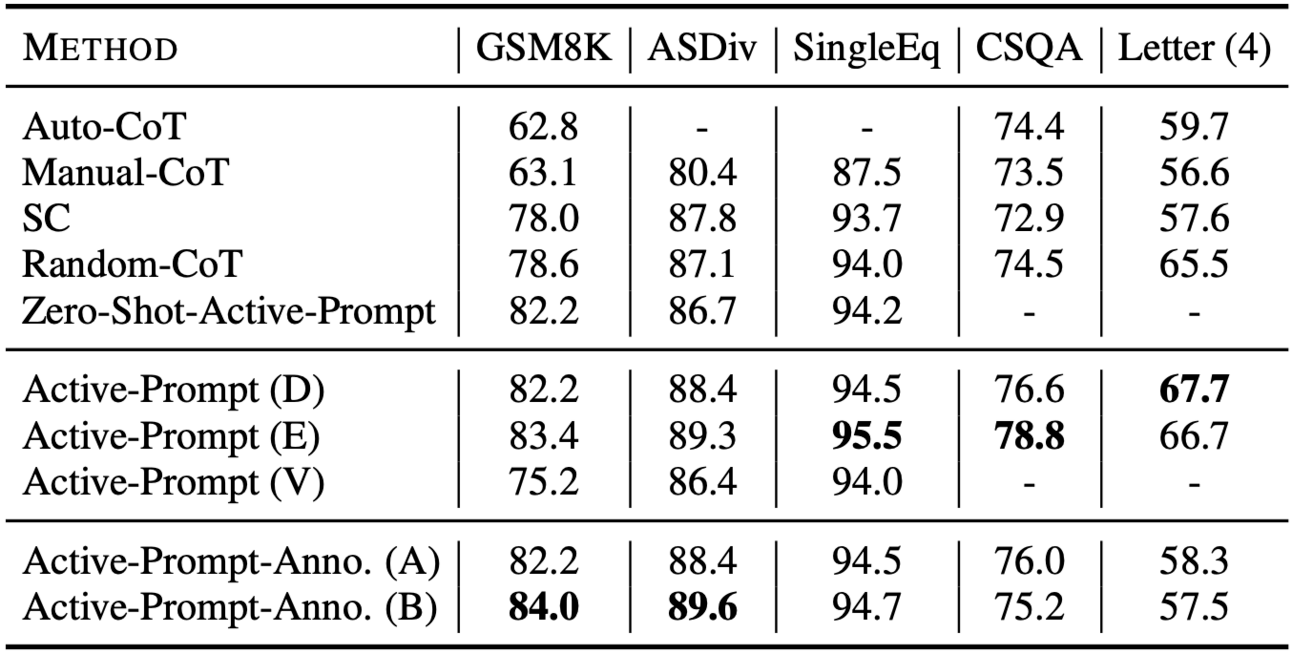
Table 2: Ablation study on three arithmetic reasoning tasks, CSQA, and Letter (4). Zero-Shot-Active-Prompt denotes the removal of the dependence of few-shot CoTs during uncertainty estimation. Anno. (A) and Anno. (B) are two different annotators. (D), (E), and (V) denote the disagreement, entropy, and variance, respectively. Bold represents the best among each dataset. The results of GSM8K, ASDiv, SingEq are obtained with code-davinci-002 while the results of CSQA and Letter (4) are obtained with text-davinci-002.
Image credit to Shizhe Diao, et al. (2024)
Key Points:
Evaluation: Tested on arithmetic, commonsense, and symbolic reasoning tasks.
Baselines: Active-Prompt surpasses CoT, SC, and Random-CoT.
Efficiency: Reduces human effort while boosting performance.
Robustness: Effective across diverse datasets and tasks.
Explanation of Active Prompting and Experimental Settings
Active Prompting is a method that refines the exemplar selection process in CoT prompting by identifying and annotating the most uncertain questions. This approach begins with estimating uncertainty for a set of questions, selecting those with the highest uncertainty for annotation, and using these annotations to guide LLM responses. For example, in tasks like GSM8K, uncertainty metrics such as disagreement and entropy help determine which questions, if annotated, would enhance model performance the most. The experimental settings involve running LLM inference multiple times to derive a pool of predicted answers, from which uncertainty is calculated. These experiments utilize datasets spanning various reasoning requirements, and models such as CodeX and GPT-3.5-turbo are employed to ensure comprehensive evaluation. The findings confirm that Active Prompting substantially improves accuracy and reasoning quality, especially when applied in few-shot learning settings.

Table 4: Comparison with weaker models. Bold represents the best among each dataset.
Image credit to Shizhe Diao, et al. (2024)
Key Points:
Active Prompting: Selects most uncertain questions for annotation.
Process: Involves uncertainty estimation to guide exemplar selection.
Experimental Setup: Uses repeat inference and diverse reasoning datasets.
Impact: Enhances accuracy and reasoning quality in LLMs.
Conclusions and Future Directions
The paper concludes by affirming the effectiveness of Active-Prompt in improving LLM performance on complex reasoning tasks through strategic question selection and annotation. The method demonstrates significant improvements in accuracy compared to traditional CoT approaches, supporting its potential as a scalable solution for enhancing LLM reasoning capabilities. The authors suggest future research directions, including exploring more diverse and complex datasets, integrating additional uncertainty metrics, and refining annotation processes to further reduce human intervention. They also propose investigating the transferability of Active-Prompt across different LLM architectures and exploring its applications beyond the current scope. Overall, Active-Prompt sets a promising precedent for optimizing prompt selection in LLMs, paving the way for more efficient and effective artificial intelligence systems.

Active Prompting with Chain-of-Thought for Large Language Models
Image credit by Cobus Greyling | Medium
Key Points:
Effectiveness: Active-Prompt significantly improves reasoning performance.
Future Research: Includes exploring diverse datasets and refining processes.
Transferability: Potential use across different LLM architectures.
Impact: Sets a precedent for optimizing prompt selection in AI systems.
For reading the full text click here
Full getting access to our Prompt Inventory check here
Don’t forget to visit our LinkedIn Page
Cutting-Edge AI Insights for Academia

The Nobel Prize in Physics 2024

The Nobel Prize in Physics 2024 was awarded jointly to
John J. Hopfield and Geoffrey E. Hinton
"for foundational discoveries and inventions that enable machine learning with artificial neural networks"
The Nobel Prize in Chemistry 2024

The Nobel Prize in Chemistry 2024 was divided,
one half awarded to David Baker "for computational protein design",
the other half jointly to Demis Hassabis and John M. Jumper "for protein structure prediction"
The Sveriges Riksbank Prize in Economic Sciences in Memory of Alfred Nobel 2024

The Sveriges Riksbank Prize in Economic Sciences in Memory of Alfred Nobel 2024 was awarded jointly to Daron Acemoglu, Simon Johnson and James A. Robinson "for studies of how institutions are formed and affect prosperity"
The Nobel Prize in Physiology or Medicine 2024

The Nobel Prize in Physiology or Medicine 2024 was awarded jointly to Victor Ambros and Gary Ruvkun "for the discovery of microRNA and its role in post-transcriptional gene regulation"
The Nobel Peace Prize 2024

The Nobel Peace Prize 2024 was awarded to Nihon Hidankyo "for its efforts to achieve a world free of nuclear weapons and for demonstrating through witness testimony that nuclear weapons must never be used again"
The Nobel Prize in Literature 2024

The Nobel Prize in Literature 2024 was awarded to Han Kang "for her intense poetic prose that confronts historical traumas and exposes the fragility of human life"
Paper of the week: Artificial neural networks, by J.J. Hopfield (1988)

Spotlight on AI Tools for Academic Excellence

Knowliah: The Power of Knowing; Knowliah dramatically improves your corporate legal department’s ROI by centralizing all legal processes in one solution: From contract lifecycle management to legal knowledge management, enterprise search and more.
Spellbook.legal: Draft and review contracts 10x faster with AI Spellbook uses AI to review and suggest terms for your contracts, right in Microsoft Word.
Accure SecureGPT: Generative AI with enterprise private data
Tonkean Legalworks: Legal experience that works. Matter lifecycle management - from intake to resolution. Triage all inbound requests with Tonkean AI. Automate simple requests. Coordinate with lawyers when needed.
Contractworks: A simple and scalable contract management software that's set up in minutes. Gain full control of your contract lifecycle end-to-end, draft perfect agreements, improve contract visibility, and never miss another renewal date.
For finding more featured and selected AI tools & apps, please subscribe to ScholarSphere Newsletter Series
Reply